Redis: The Context & Memory Layer for AI Agents
Redis is positioning itself as the memory and context layer for AI agents.
Instead of relying only on vector search and RAG, Redis provides:
- Agent Memory for long-term memory and state.
- Context Retrieval to pull relevant data from enterprise systems.
- LangCache to reduce unnecessary LLM calls.
- Iris to keep agent context updated in real time.
The goal is for the LLM to focus on reasoning, while Redis handles memory, context, retrieval, and caching.

Quick Navigation
-
1
The Four Essentials of a Context Strategy
According to Redis, effective context for AI agents should be:
- Dynamically Navigable: Agents should be able to explore and connect information across multiple sources rather than relying on a single retrieval operation.
- Fast to Retrieve: Context retrieval should happen in milliseconds. Slow retrieval directly impacts user experience and increases latency.
- Improve With Usage: The system should learn from interactions and build memory over time.
- Always Up to Date: Static snapshots quickly become outdated. Agents need access to live data whenever possible.
These four principles become increasingly important as AI systems move beyond simple chatbots into autonomous agents.

-
2
Traditional RAG Is Linear
Standard RAG architectures follow a linear pattern: retrieve documents, inject them into a prompt, and generate a response.
Question ↓ Vector Store ↓ LLM ↓ Answer
This works well for basic knowledge bases and static documentation search. However, the model has no ability to discover additional context dynamically unless developers explicitly build custom multi-step pipelines. As reasoning capabilities improve, this linear architecture becomes a limiting bottleneck.

-
3
The Core Problem with RAG
The presentation illustrated a real-world customer support example to showcase the limits of standard RAG.
When a user asks, "Why is my order late?", a traditional RAG system retrieves a general help desk article on delivery delays. While technically correct, the answer is generic and unhelpful. The system lacks access to critical operational context:
- Which order belongs to the user
- Current live delivery status
- Driver information and tracking
- Customer support history
- Refund policies relevant to that specific order
"Documents are not context."
The correct answer requires access to multiple structured and live data sources, not just document retrieval from a vector database.

-
4
Context Exists Everywhere
Relevant information is fragmented across an organization's entire data ecosystem. An agent might need to pull context from:
- Relational Databases (SQL): Customer records, transaction histories.
- External APIs: Real-time shipping data, weather, tracking APIs.
- Session Stores: User state, recent web actions.
- Data Warehouses & Time-series: Historical analytics, temporal trends.
- Vector Stores: Semantic documents, unstructured text.
- Long-term Memory Systems: Past interactions and preferences.
The core challenge is not the LLM's generation capability, but rather connecting all these disparate systems to the agent in a usable, unified, and low-latency way.

-
5
Proposed Solution: A Unified Context Layer
Redis argues that AI architectures need a semantic access layer sitting directly between the agent and the various data sources. Rather than forcing the agent to query multiple systems independently, a unified context retrieval layer handles the complexity and provides clean access to:
- Structured Data: Orders, customer accounts, inventory, and transaction states.
- Unstructured Data: PDFs, documentation, help tickets, and internal knowledge bases.
- Memory: Conversation histories, user preferences, and historical agent decisions.
This abstraction simplifies agent design, ensuring the model receives a unified context package regardless of where the data originates.
-
6
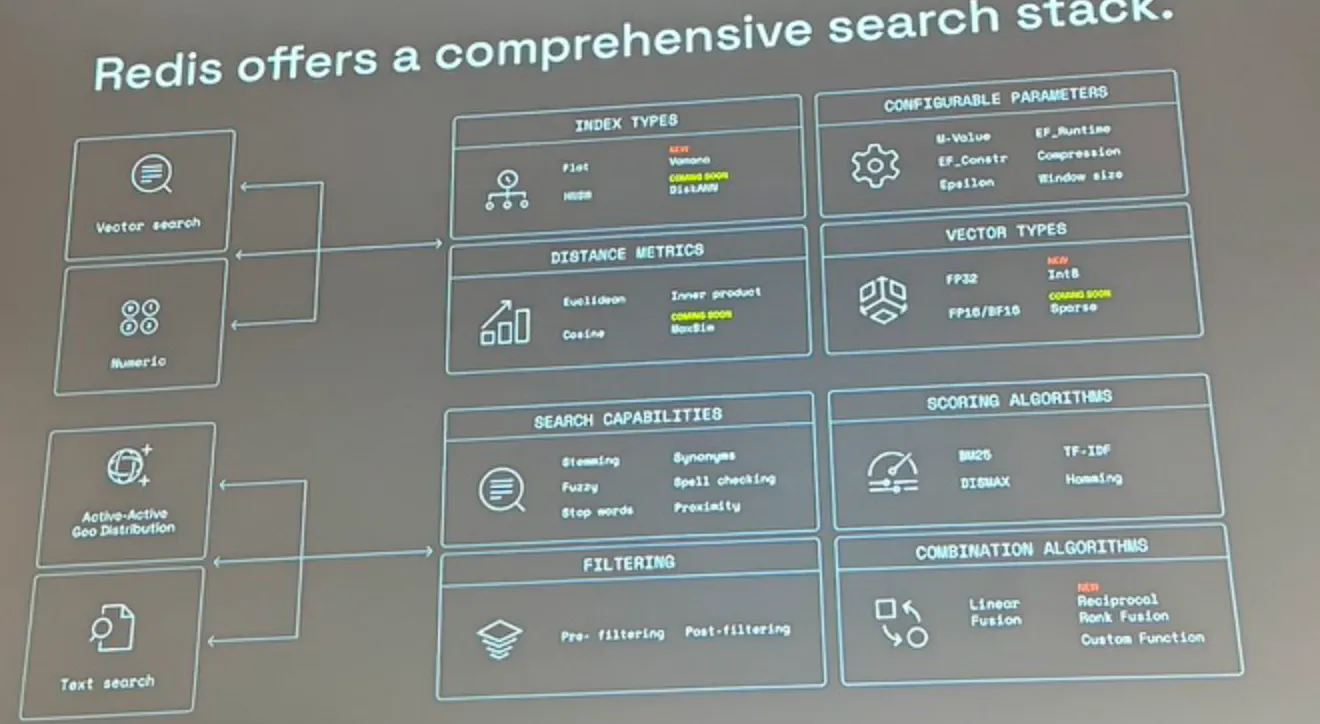
Redis Search Is More Than Vector Search
Redis is shifting its position from a simple caching layer to a comprehensive search and retrieval platform. It offers hybrid retrieval by combining several capabilities:
- Search Capabilities: Vector similarity search, full-text search, numeric filters, and geospatial queries.
- Advanced Search Features: Fuzzy matching, synonym dictionaries, word stemming, and spelling correction.
- Ranking Methods: Support for classic text scoring models like BM25 and TF-IDF, as well as custom hybrid scores.
This allows applications to run hybrid queries, finding documents that are both semantically similar and match strict metadata filters (e.g., date ranges, locations, or numeric values) in a single pass.

-
7
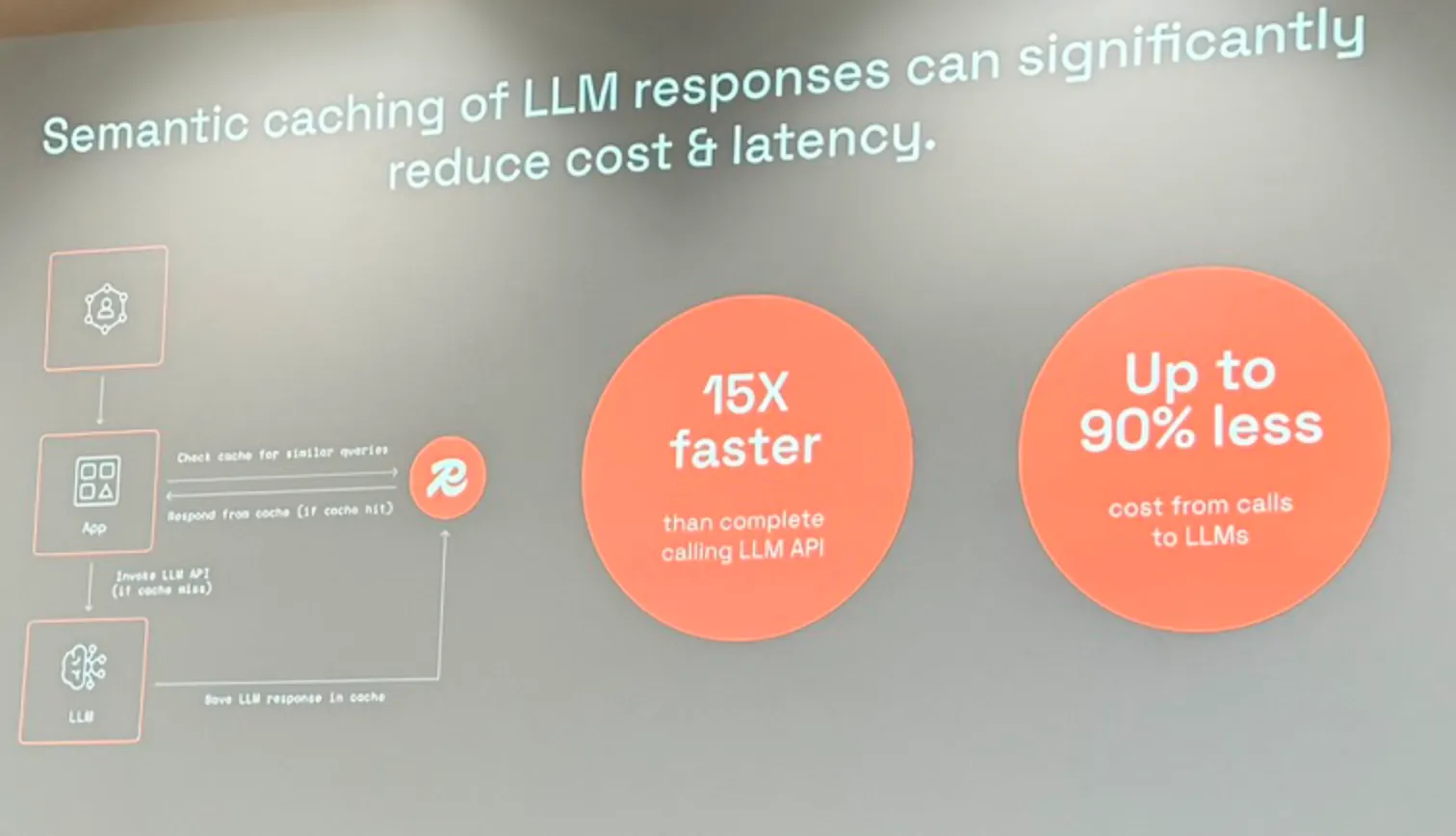
Semantic Caching
Traditional caching relies on exact key/value string matching. If a user changes a single letter or word, the cache misses.
Semantic caching works differently. If a new user query is semantically similar to a previously answered question (based on distance metrics in vector space), the system returns the cached response directly without running the query through the LLM again.
Question A: "What is the PTO policy?"
Question B: "How many vacation days do employees get?"
Result: Match detected! Returns cached Answer A without invoking the LLM.
According to Redis, implementing semantic caching can result in:
- Up to 15x lower latency for repeated or equivalent queries.
- Up to 90% lower LLM costs by preventing redundant token processing.
-
8
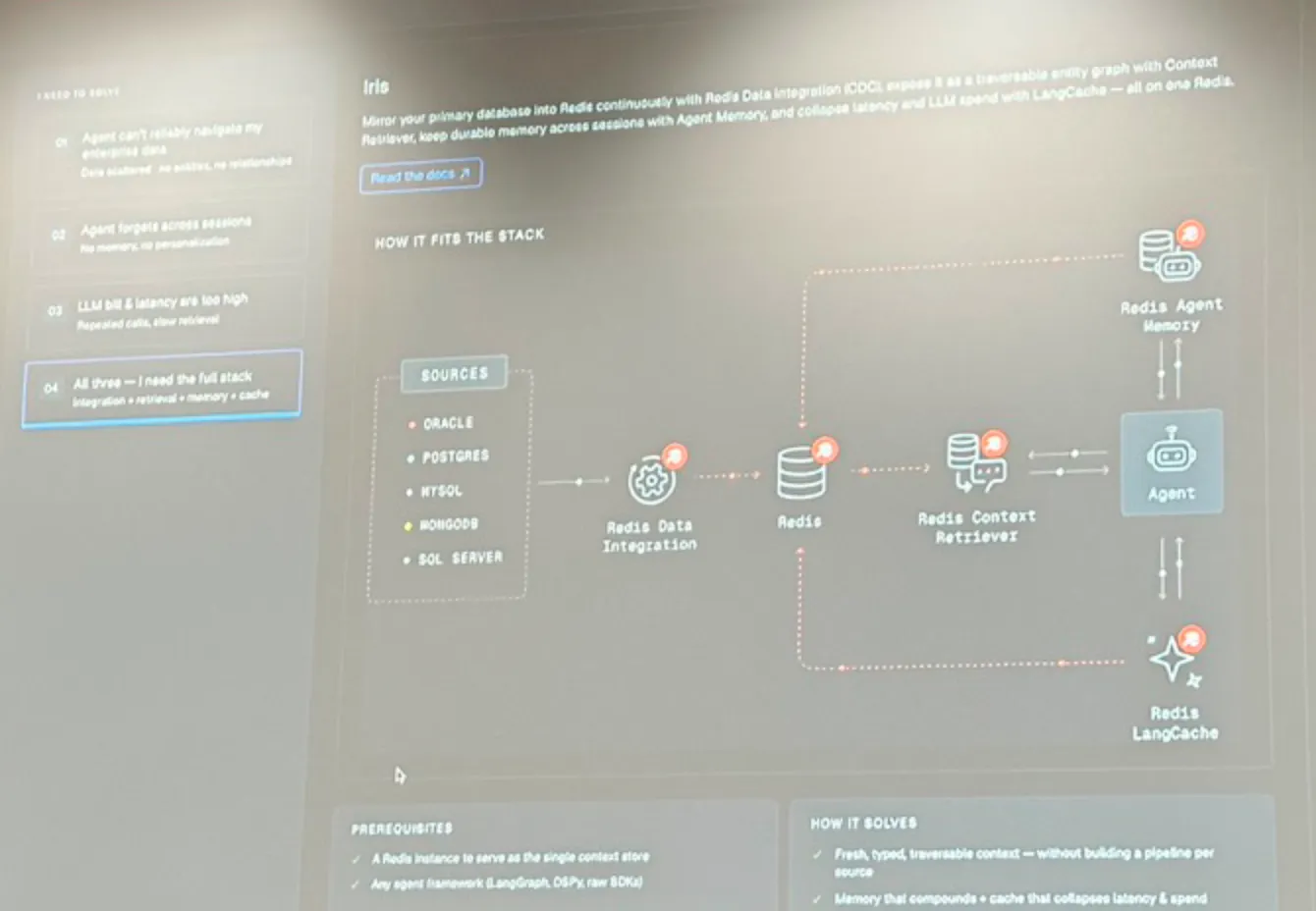
Redis Iris & Agent Memory Strategy
The presentation introduced Redis Iris as a unified context platform. It combines data integration (synchronizing relational databases like Oracle, PostgreSQL, MySQL, SQL Server, and MongoDB), context retrieval, short/long-term agent memory, and semantic caching.
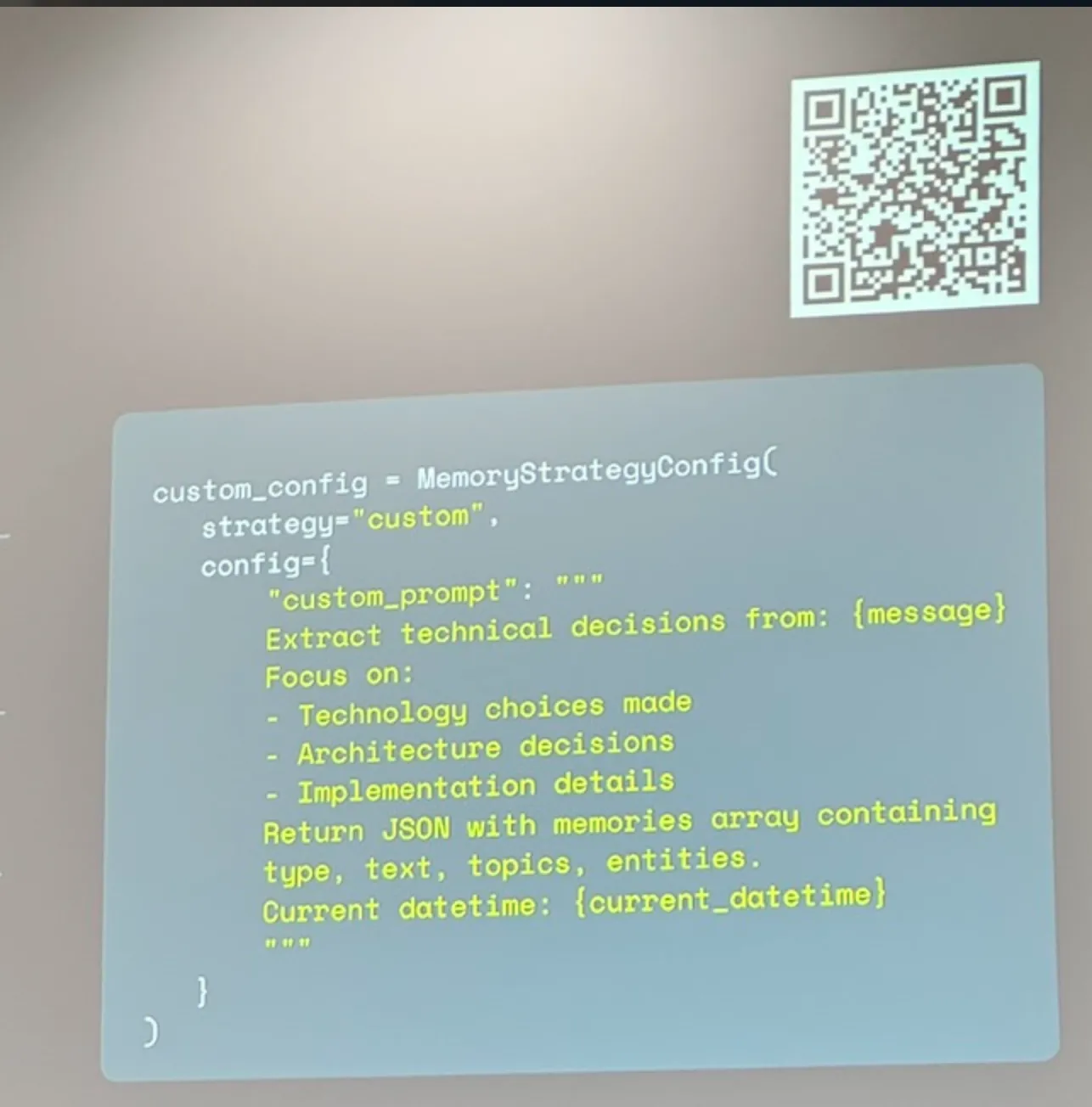
A key focus of Redis Iris is its strategy for Agent Memory. Storing full chat logs quickly exceeds context windows and floods the system with noise. Instead, Redis Iris supports structured memory extraction. For example, it extracts:
- Technology choices and preferences.
- Architecture decisions and patterns.
- Implementation details and state configurations.
Key Takeaways
- RAG is Becoming Infrastructure: Document retrieval is no longer the final goal; it is a single component within a larger context orchestration layer.
- Memory Matters: Effective agents rely on curated short-term and long-term memory structures rather than raw conversation histories or basic document searches.
- Context Engineering: Prompt engineering is maturing into context engineering. The success of an AI app is defined by how context is dynamically integrated, updated, and retrieved.
- Multi-Source Retrieval: Real-world operational answers require connecting vector databases with traditional SQL databases, APIs, session states, and active memories.
"The future of AI applications is defined by context management as much as by the capabilities of the underlying LLM itself."